Sampling Example
Let's step through a few Rason data science examples now. Let's start with an example of how to sample from a dataset.
{
"modelName": "Sampling",
"modelDescription": 'transformation: sampling',
"modelType": 'datamining',
"datasources": {
"mySrc": {
"type": "csv",
"connection": "hald-small-binary.txt",
"direction": "import"
}
},
"datasets": {
"myData": {
"binding": "mySrc"
}
},
"transformer": {
"mySampler": {
"type": "transformation",
"algorithm": "sampling",
"parameters": {
"sampleSize": 4,
"replaceOption": "false",
"sortIndexes": "false",
"seed": 123
}
}
},
"actions": {
"sampleData": {
"data": "myData",
"action": "transform",
"evaluations": [
"transformation"
]
}
}
}
Within "datasources" a sample is taken from the hald-small-binary dataset (contained within hald-small-binary.txt) and given the name
"mySrc". This file contains data in CSV format.
Note: Input files in a Data Science Rason model must not contain a path to a file location.
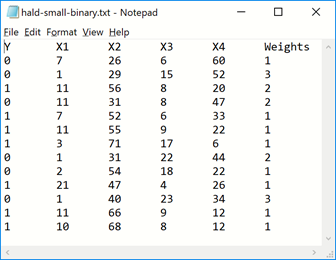
Within "datasets", the data sampled in mySrc is bound to myData. The sampling transformer, mySampler, is specified within the
"transformer" attribute. Since we are sampling, the "type" is specified as "transformation" and the algorithm is specified as "sampling".
Various sampling options under "parameters": sample size (sampleSize), sample with replacement (replaceOption), index sorting (sortIndexes) and the random seed value (seed). For a complete list of options associated with the sampling transformer, please see the RASON Reference Guide.
Finally, under "actions", the transformation (the sampling) is performed on the myData dataset. Under "evaluations" we see the
quantities to be computed and reported. In this example, the sample is the result.
Getting model results: GET https://rason.net /api/model/ 2590+Sampling+2020-01-20-01-07-51-620648/result
"sampleData": {
"transformation": {
"objectType": "dataFrame",
"name": "Sample:mydata",
"order": "col",
"rowNames": ["Record 5", "Record 3", "Record 9", "Record 7"],
"colNames": ["Y", "X1", "X2", "X3", "X4", "Weights"],
"colTypes": ["double", "double", "double", "double", "double", "double"],
"indexCols": null,
"data":[
[1,1,0,1],
[7,11,2,3],
[52,56, 54,71],
[6,8,18,17],
[33,20,22,6],
[1,2,1,1]
]
}
}
Getting model results: GET https://rason.net /api/model/2590+Sampling+2020-01-20-01-07-51-620648/result
{
"status": {
"id":"2590+Sampling+2020-01-20-01-07-51-620648",
"code":0,
"codeText": "Success"
},
"results": [sampleData.transformation"],
"sampleData": {
"transformation": {
"objectType": "dataFrame",
"name": "Sample:mydata",
"order": "col",
"rowNames": ["Record 5", "Record 3", "Record 9", "Record 7"],
"colNames": ["Y", "X1", "X2", "X3", "X4", "Weights"],
"colTypes": ["double", "double", "double", "double", "double", "double"],
"indexCols": null,
[1,1,0,1],
[7,11,2,3],
[52,56,54,71],
[6,8,18,17],
[33,20,22,6],
[1,2,1,1]
]
}
}
}
According to the results, the records sampled were:
Sampling Results
| Index |
Y |
X1 |
X2 |
X3 |
X4 |
Weights |
| 5 |
1 |
7 |
52 |
6 |
33 |
1 |
| 3 |
1 |
11 |
56 |
8 |
20 |
2 |
| 9 |
0 |
2 |
54 |
18 |
22 |
1 |
| 7 |
1 |
3 |
71 |
17 |
6 |
1 |
A Note about Data Frames
A DataFrame, in Rason Data Services, is a collection of data organized into named columns of equal length and homogeneous type. Rason DM uses DataFrames to deliver input data to an algorithm and to deliver the results of the algorithm back to the user. DataFrames hold heterogeneous data across columns (variables): numeric, categorical, or textual.
Examples of basic DataFrame tasks are:
Creating and filling DataFrames
Selecting a subset of columns/rows
Appending columns or rows
Selecting subsets for training and verification models
RASON V2020 introduces two new REST API endpoints POST rason.net/api/solve and POST rason.net/api/model/{nameorid}/solve which automatically create an OData endpoint which returns the result in a dataframe object. For more information, see the Using the REST API topic.
|